Are frontier labs making 80+% gross margins on LLM inference?

Rare insights into gross margin profile for a LLM model provider
Recently, as part of their open source week, DeekSeek disclosed their online inference system design and performance statistics. This system serves all of DeepSeek’s first-party model services (API and chat services).
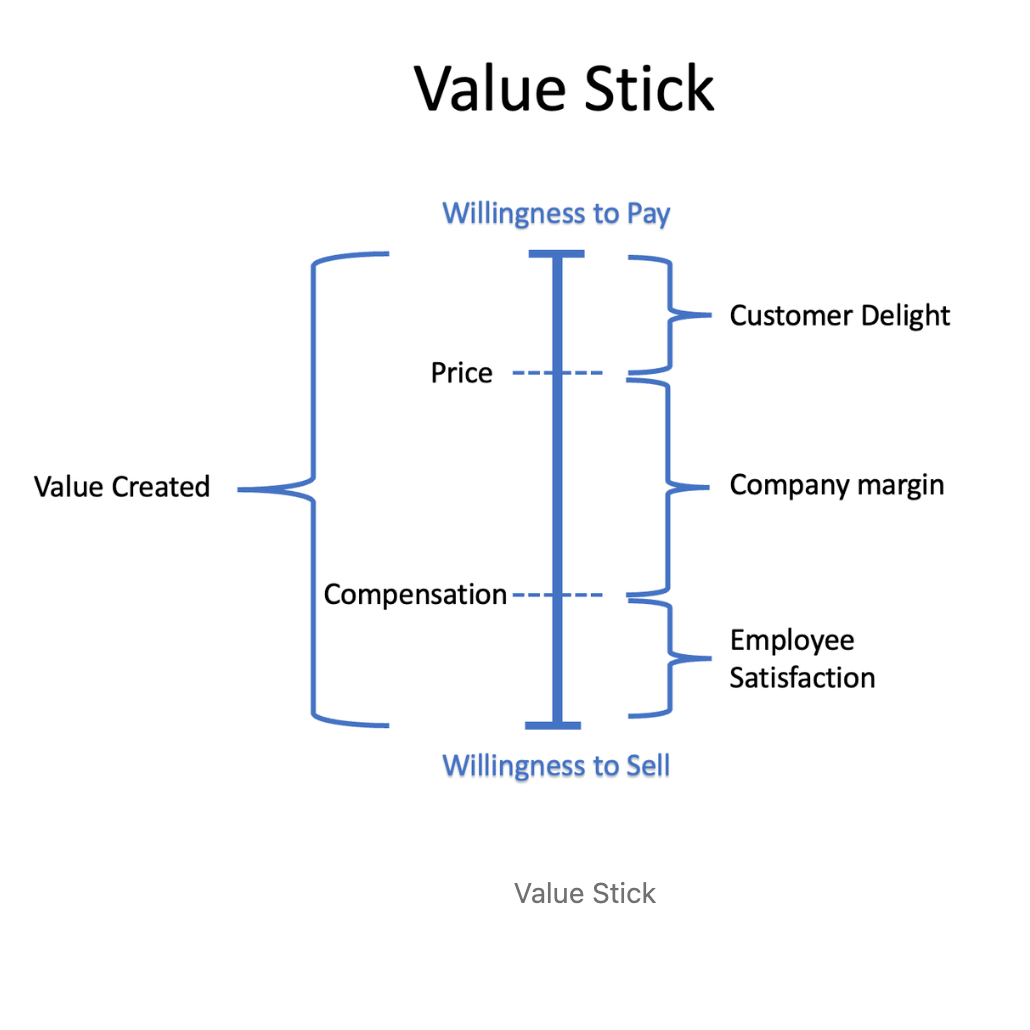
Over a single day, DeepSeek utilized an average of 1,814 H800 GPUs (up to 2,224 GPUs at peak loads) to serve all of its inference workloads. H800 GPUs are US export-eligible variants of NVIDIA’s H100 GPUs.
At the moment, H100 GPUs are likely around ~$1.75 to ~$2.50 (per GPU per hr) on a long-term reserved basis. Using the same $2.00/H800 gpu/hr assumption as DeepSeek, their daily GPU inference costs are $87,072 for the entire inference cluster.
Currently, only usage of DeepSeek’s API services are monetized. Their chat services (via the web and mobile app) continue to be free.
Using the current DeepSeek R1 API pricing, the company said it could theoretically generate about ~$562k in daily revenues, representing ~84.5% in gross margins.
Extrapolating from DeepSeek, how much margins could other providers be making?
Mostly as a thought experiment, if other labs were able to incur some multiple N of DeepSeek’s inference cost structure, what would be their gross margins?
With DeepSeek R1’s very low pricing, they are already able to produce ~85% in gross margins.
If OpenAI served gpt-4o and Anthropic served claude-3.7-sonnet at the 1x DeepSeek’s cost structure, they would be making ~96.9% and ~97.5% gross margins!
Now, that may not yet be realistic as DeepSeek’s innovations do not transfer instantaneously to other labs. It will take some time for these labs to absorb the same cost improvements into their sprawling model training pipeline, and then into their inference systems.
But if we take a less favorable view, and assume OpenAI and Anthropic’s gpt-4o and claude-3.7-sonnet cost structures are 5x less efficient than DeepSeek.
Astonishingly, the less favorable gross margins are still ~84.3% and 87.3% respectively!
What kind of trade-offs did DeepSeek make?
DeepSeek’s V3 and R1 models created a lot of shock and awe early in the year.
Their transformer architecture improvements likely contributed significantly to their ability to serve V3 and R1 so cheaply with much less GPUs. Their MLA (multi-latent attention) innovation significantly reduced the Key-Value cache requirements, allowing them to parallelize the attention computations across much larger batch sizes (without running out of memory).
High batch sizes lead to higher throughput, at the cost of latency. Higher throughput means higher utilization of GPUs, and thus lower costs. You can read much more in-depth explanations on inference system trade-offs from Google.
Because their mixture-of-experts (MoE) has a very high sparsity factor (256 experts; 8 activated), they also need to utilize larger scale cross-node expert parallelism to achieve optimal load balancing for the high batch size.
As a result, Deepseek’s inference is much slower than other providers. DeepSeek is as slow as OpenAI’s recently released gpt-4.5; which is accepted to be a much larger model (larger models are slower to serve, and thus more costly).
